Nach dem groß angekündigten Tischtennismatch zwischen einem KUKA-Roboter und Timo Boll hat Jörn 2014 hier im Blog einen erbosten Kommentar geschrieben. Das angekündigte Match stellte sich nämlich leider als ziemlich trauriger Marketing-Stunt heraus, bei dem außer schnellen Kameraschnitten und CGI nicht viel zu sehen war.
Dass es auch anders geht, zeigt der Roboterhersteller Omron in disem Jahr wieder auf der CES 2020 in Las Vegas:
https://youtube.com/watch?v=T-5-Ebh2E6c
Das Spiel kann sich durchaus sehen lassen, finde ich. In einem Video aus dem letzten Jahr kann man sogar sehen, wie der Roboter im Zusammenspiel mit einem klassischen Roboterarm einen recht ansehnlichen Aufschlag macht (ab 0:30):
Im Hintergrund ist auf dem Monitor zu sehen, wie die ganze Zeit nicht nur der Ball von Kameras getrackt wird, sondern auch die Pose des menschlichen Mitspielers. In den Videos ist auch zu sehen, wie nützlich dabei auch die Bauart ist. Delta-Roboter sind für ihre flinken uns präzisen Bewegungen bekannt. Siehe dazu auch unseren Beitrag aus dem Jahr 2009: 400 pancakes per minute.
Diese Roboter baut Omron natürlich nicht für’s Tischtennisspielen allein. Das ist lediglich eine ziemlich coole Attraktion, um die Fähigkeiten des Roboters auf Messen zu zeigen (und vielleicht auch eine kleine Spitze gegen KUKA?). Wenn der Omron-Roboter nicht gerade mit Tischtennis beschäftigt ist, ist sein Einsatzgebiet nämlich Pick & Place. Ein klassisches Aufgabenfeld für Delta-Roboter, bei dem ähnliche Fertigkeiten gefordert sind, siehe Adept Quattro: Fünf pro Sekunde. Der Roboter in dem verlinkten Artikel ist übrigens von Adept, die 2015 von Omron aufgekauft wurden.
Ich hatte den Blogeintrag schon fertig geschrieben, wollte von meinem geplanten fünften Besuch bei einem European Robotics Forum (ERF) in diesem Jahr erzählen, da hab ich doch noch einmal zur Sicherheit nachgesehen: es ist in diesem Jahr sogar schon mein sechstes ERF. Vergessen hatte ich meine erste Teilnahme, 2012 in Odense. Damals, genau wie beim ERF 2013 in Lyon, noch als Doktorand von der Uni, jetzt seit 2016 in Ljubljana, 2017 in Edinburgh und 2018 in Tampere als Mitarbeiter von Bosch.
In diesem Jahr, übernächste Woche, findet das ERF in Bukarest in Rumänien statt. Nachdem ich seit Jahren darauf hinwirke, wird sich dieses Mal mein Arbeitgeber, Bosch Research, auch etwas präsenter zeigen und mit Sponsoring und einem Ausstellungsstand beteiligen.
Ich selbst werde als einer von zwei Koordinatoren der Topicgroup zu Software Engineering, System Integration und System Engineering in der Robotik wie auch im letzten Jahr wieder einen Workshop ausrichten, sowie am letzten Konferenztag einen Kurzvortrag zu Safety in der Robotik halten. Abseits davon wird es mir wieder hauptsächlich darum gehen, die aktuelle Stimmung in der europäischen Robotik mitzubekommen, Bekannte aus der Robotik wieder zu treffen, neue Roboter zu sehen und wahrscheinlich werde ich mich auch regelmäßig mal am Bosch-Stand sehen lassen.
Ich freue mich über jeden Leser, der auch in Bukarest ist, mich anspricht und mit mir tagsüber einen Kaffee oder abends beim Social Event mit mir anstößt.
Disclaimer:Ich bin Mitarbeiter der Robert Bosch GmbH und forsche dort an Robotern und autonomen Systemen. Die hier geäußerten Meinungen und Ansichten sind allerdings ausschließlich persönlich und stimmen nicht zwingend mit der Unternehmenssicht überein.
Die Robotik-Landschaft ist um eine weitere Website reicher, die es in sich hat. https://robots.ieee.org ist eine (zur Zeit noch ausschließlich englischsprachige) Sammlung von über 200 Robotern aus 19 Ländern und enthält alles, was in der Robotik Rang und Namen hat: ASIMO, Aibo, Pleo, … viele Roboter, die hier im Blog auch schon Thema waren, z.B. Roomba, iCub, der gruselige CB2, der niedliche Keepon, usw.
Quelle: IEEE Spectrum
Alle Roboter sind mit fantastischen Bildern, Videos und Hintergrundinformationen ausgestattet (im Moment noch alles auf Englisch). Bei ASIMO lassen sich zum Beispiel die Prototypen sehen, die Honda seit dem Start seiner Entwicklung 1986 gebaut hat.
Die Website ist eine wunderbare Sammlung, die weiter wachsen wird und unter Anderem zum Ziel hat, Schüler für Roboter und damit für (Ingenieurs)-Wissenschaften, Mathematik und Technik zu begeistern.
Via @Generation Robots DE auf twitter bin ich auf einen Artikel der elektrotechnik aufmerksam geworden. Der Artikel „Die Geschichte der Automatisierung“ ist eine tolle Zeitreise, angefangen im Januar 1968 mit den ersten Ideen für speicherprogrammierbare Steuerungen (SPS) bis hin zum modernen Internet of Things (IoT).
Räderwerke als Beispiel früher Automatisierung.
Strenggenommen startet der Artikel sogar in der Antike mit Huldigung der Göttin „Automatia“ und Räderwerken von antiken Automaten-Theatern. Es geht durch die Zeit über die Dampfmaschine, SPS, die 1980er Jahre mit den ersten PCs für Computer Integrated Manufacturing, und so weiter…
Eine mittlerweile beliebte Frage auf Messen und Konferenzen, auf denen Hersteller der neuen Generation kollaborativer Roboter als praxistauglich preisen ist: Wie viele eurer Roboter setzt ihr denn selbst bei der Herstellung eurer eigenen Roboter ein?
Die Antwort war bislang in aller Regel ernüchternd: Der KUKA iiwa wird handgefertigt, Baxter habe ich bislang nicht viel mehr als das Aufheben von Objekten machen sehen (und Rodney Brooks musste die Frage auf einer Konferenz auch verneinen), und meine diesbezügliche Frage beim Bosch APAS wurde auch zögerlich bis ausweichend beantwortet.
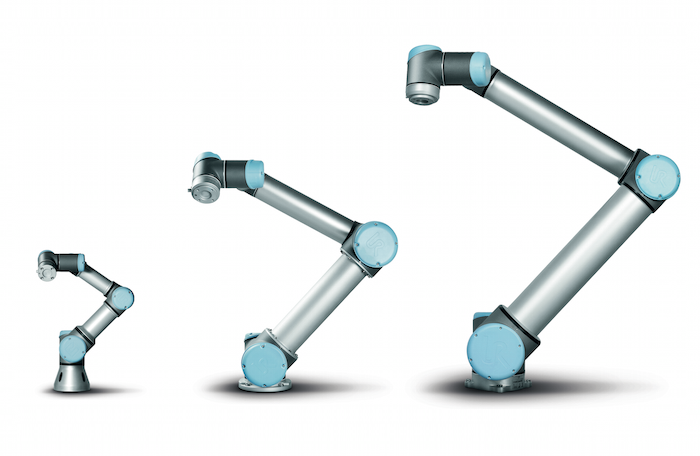
Der dänische Roboterbauer Universal Robots, das seit einigen Jahren mit günstigen und kraftgeregelten Leichtbaurobotern den internationalen Robotermarkt aufräumt, scheint das nun zu ändern. Der neu vorgestellte Universal Robots UR3 ist genau für Fertigungsarbeiten und Werkstattaufgaben gemacht und wird daher Universal Robots eingesetzt, um Kopien von sich selbst herzustellen 1 :
“Our robots are indeed helping to build our robots.” — Esben Østergaard, CTO und Mitgründer von Universal Robots
So sollte es sein. Wenn sie stimmt, gibt mir diese Aussage Vertrauen in die Praxistauglichkeit des Roboters. Und umgekehrt: Wenn der Hersteller seine Produkte selbst nicht einsetzt, warum sollte ich glauben, dass sie mir helfen können?
tl;dr: Der neue Universal Robots UR3 wird von Universal Robots beim Bau seiner eigenen Kopien eingesetzt. Und das ist gut so!
Die Universal Robots UR10, UR5 (von rechts) und links der neue kleine UR3.
In der vergangenen Woche fand das European Robotics Forum statt. Dabei handelt es sich um eine Networking-Veranstaltung, bei denen aktuelle und zukünftige Trends in der europäischen Forschungslandschaft diskutiert werden. Einem Blick ins Programm der Veranstaltung verrät bereits einen guten Überblick, was die deutsche Robotik Gemeinde umtreibt. Ein wesentlicher Aspekt ist es, die Verknüpfung zwischen Wahrnehmung und Handlung in Robotern zu verbessern. Es geht darum, einen Roboter in die Lage zu versetzen, komplexe Bewegungen und Manipulationsaufgaben, die einen hohen Grad an Geschick erfordern, selbstständig oder durch Demonstration zu erlernen und zu adaptieren.
In meinen Augen ist das ein hochspannendes Thema, in dessen Kontext ich vor etwas längerer Zeit bereits auf nachfolgende beeindruckende Videos aufmerksam geworden bin:
Das Video zeigt, wie ein Mensch einem Roboter das Tischtennis Spielen demonstriert. Anschließend erprobt und verbessert der Roboter selbstständig seine Fähigkeiten. Schließlich, spielt der Roboter Tischtennis mit einem Menschen.
Der Tischtennis Demonstrator ist meiner Ansicht nach sehr gut geeignet um Forschungsergebnisse dieser Art darzustellen. Es gibt viele Freiheitsgrade. Die Dynamik der Aufgabe ist hoch und fordernd. Eine Tischtennisplatte hat vertretbare Abmessungen, sodass sich der Demonstrator in einem Labor gut realisieren lässt. Das Spiel mit einem echten Menschen ist nicht planbar. Es kommt zu unvorhersehbaren Ballwechseln. Daher demonstriert das Experiment prinzipell sehr gut die Generalisierungsfähigkeit aber auch die Grenzen entwickelter Algorithmen.
Hohe Erwartungen
Im Februar kündigte der Roboterhersteller KUKA mit nachfolgendem Video ein Tischtennis Duell zwischen einem KUKA Roboter und dem Tischtennisprofi Timo Boll an.
Vor dem Hintergrund der zuvor dargestellten Forschungsarbeiten war ich natürlich freudig gespannt auf das Event. Und damit war ich nicht allein. Aus den Kommentaren:
„Hmm…ein Fake wird es nicht sein, glaube aber nicht das der Bot den Hauch einer Chance gegen Boll hat, sobald der mit Topspin angreift. […]“
„Fantastic. Cant wait to see this in action…“
„Well…never thought I’d be so hyped for a ping pong match!“
Auf IEEE Spectrum News schreibt Evan Ackermann: „Wow, Kuka wouldn’t have set this whole thing up unless it was actually going to be a good match! Maybe we’ll see some amazing feats of high speed robot arms, vision systems, and motion tracking!“
Ernüchterung
Die geschürte Erwartung bestand in einem tatsächlichen „Duell“ im Sinne eines echten Spiels zwischen Mensch und Roboter. In meinem durchaus robotisch geprägten Umfeld wurden rege Diskussionen geführt, wie das hypothetische Match ausgehen würde. Ebenso wurden Vermutungen über technische Realisierungen diskutiert. Die oben angesprochenen Forschungsergebnisse haben die prinzipielle Machbarkeit ja bereits vor einiger Zeit demonstriert. Bis hier her: schöne Arbeit seitens des Marketings. Das mit Spannung erwartete Duell war in aller Munde. Am 10.03. erschien dann das ernüchternde Video:
Für sich genommen ein nettes Werbe-Video. Aber nicht das angekündigte Spiel zwischen Mensch und Maschine. Nur ein mit Spezialeffekten voll gepumpter Trickfilm. Die Story: erst dominiert der Roboter, dann reißt Timo das Ergebnis noch einmal mit spektakulären Spielzügen rum. Die wohl beabsichtigte Botschaft des Roboterherstellers wird am Ende noch einmal explizit formuliert:
„Not the best in table tennis. But probably the best in robotics.“
Die in meinem Umfeld gespiegelte Botschaft fiel eher anders aus. Sie war mehr von Enttäuschung geprägt. Herauszuhören war zusammenfassend: „KUKA hat ein Duell versprochen, aber nur einen Trickfilm geliefert.“ Auch das spiegelt sich in den sozialen Netzwerken wieder:
„Agreed, great idea for marketing, but poorly developed“
„I was so excited to see a duel between a robot and a world champion in table tennis. Expectations were like Kasparov vs Deep Blue, right? Turns out it’s just a very well shot but fake commercial.“
Evan Ackermann trifft auf IEEE Spectrum News den Nagel auf den Kopf: „But the encounter wasn’t the „robot vs. human duel“ we were promised. What Kuka gave us instead is an overproduced, highly edited commercial that, in our view, will puzzle (rather than amaze) those of us who follow robotics technology closely.“
In meinen Augen eine verpasste Chance, Menschen zu begeistern und durch technologische Leistung zu überzeugen.
Zu allem Überfluss erschien diese Woche dann ein weiteres Fake-Video (dieses Mal nicht von KUKA) von einem Tischtennisroboter, der angeblich in einer heimischen Garage realisiert wurde:
In der Beschreibung zum Video steht: „Nach ca. 2 Jahren Entwicklungsarbeit habe ich mit meinem Freund Michael nun unseren selbst gebauten Tischtennis Roboter soweit fertig gestellt, dass man mit ihm schon ordentliche Ballwechsel spielen kann.“ Leider ist das Video offensichtlich montiert, wie einige aufmerksame Kommentatoren anmerken:
„It is fake, look at 1:09! You can see that the camera in the upper right of the garage door is in front of the table tennis racket because it was added to the footage later.“
„Had me fooled until the close up at 2:20. Those movements don’t seem real, and it seems weird that every movement has the same sound even tough the speeds are different and so are the moves.“
camera in the upper right of the garage door is in front of the table tennis racket
Als Trickfilm-Projekt ist das Video sicherlich überzeugend gut gemacht. Das belegen auch die zum Teil auch emotional aufgeladenen Diskussionen zur Echtheit des dargestellten Experiments…
Zwei Aspekte haben mich schließlich zur Wahl des Titels für diesen Blogeintrag bewegt:
Enttäuschung
Beide Videos, das von KUKA und das Garagen-Video, haben eine unglaublich rasante Verbreitung in den sozialen Netzwerken erfahren. Für den geneigten Robotik-Laien, so befürchte ich, mag allerdings durch beide Videos ein falscher Eindruck von dem entstehen, was Roboter heute leisten können. Die damit verbundenen komplexen Problemstellungen hat Arne in einem früheren Blogeintrag bereits ausführlich thematisiert.
Darüber hinaus erscheint Tischtennis als Demonstrator für die eingangs beschriebenen Forschungsprojekte erst einmal verbraucht. Bei jeder zukünftigen Demonstration des Experiments und jedem neuen Video dazu schwingt zunächst einmal unterschwellig mit: „Schau mal, da hat wieder einer so getan, als könnte er mit einem Roboter Tischtennis spielen“. Vielleicht fällt ja jemandem ein alternativer, hinsichtlich Komplexität, Anzahl der Freiheitsgrade und Realisierbarkeit im Labormaßstab vergleichbarer alternativer Demonstrator ein?
Aus robotischer Sicht finde ich die Ereignisse in Summe also sehr schade und komme zu dem Schluss: dies war ein trauriger Monat für die Robotik.
Grundsätzlich wird die strukturelle Elastizität in Roboter-Armkörpern bislang nachteilig gesehen. Sie verlängert Ausregelzeiten und verschlechtert die Positioniergenauigkeit. Allerdings wurde die Realisierbarkeit einer schnellen und genauen Positionierung eines gliedelastichen Roboterarms anhand von Ballfang-Experimenten exemplarisch gezeigt 2. Darüber hinaus kann die intrinsische Nachgiebigkeit jedoch auch vorteilhaft dazu ausgenutzt werden, die tatsächlich effektive Nachgiebigkeit des gesamten Arms aktiv zu beeinflussen. Wie im ersten Teil zu diesem Thema bereits dargestellt, setzt dies eine Kompensation der unerwünschten Effekte durch eine geeignete unterlagerte Regelung voraus. Dabei wurde die Wahrscheinlichkeit, auch zerbrechliche Objekte im Falle einer unvorhergesehenen Kollision zu beschädigen, deutlich gemindert.
Das obenstehende Video geht einen Schritt weiter. Beabsichtigte oder auch unbeabsichtigte Kontakte werden explizit auf Basis eines Modells der gedämpften Armdynamik detektiert und ermöglichen eine entsprechende Reaktion. Das Video stellt das gliedelastische Experimentalsystem TUDOR vor und zeigt insgesamt sieben Experimente zur Schwingungsdämpfung, zur Detektion genau wiederholbarer stumpfer wie auch scharfer Einschläge auf Luftballons sowie zerbrechlicher Christbaumkugeln, weniger exakt wiederholbarer Einschläge auf einen menschlichen Arm und schließlich zur physischen Interaktion mit dem Roboter.
Die Paare von Dehnungs-Messstreifen, die in der Nähe der Gelenke auf jedem nachgiebigen Arm appliziert sind, fungieren als lastseitige Drehmomentsensoren. Unter der Voraussetzung einer hinreichenden Schwingungsdämpfung kann die verbliebene Dynamik des Arms in Analogie zu konventionellen starren Roboterarmen modelliert werden. Diese Vorgehensweise ermöglicht die unmittelbare Anwendung von Verfahren zur Kollisionsdetektion und -reaktion, wie sie zuvor bei gelenkelastischen sowie starren Roboterarmen vorgestellt worden sind 3 .
Die dargestellen Ergebnisse verdeutlichen, dass die strukturelle Elastizität in Roboter-Armkörpern nicht zwingend als nachteilig gesehen werden muss. Vielmehr können sich mit Hilfe entsprechender Regelungsansätze aus der Ausnutzung dieser Eigenschaften neue Möglichkeiten ergeben.
Wer hat sich nicht schon einmal einen Roboter gewünscht, der im Haushalt hilft? Der zum Beispiel schon einmal den Kuchenteig anrührt, knetet und ausrollt, während man selbst die Glasur vorbereitet, bzw. einem das lästige Gemüseschnibbeln beim Kochen abnimmt. Oder einen kleinen Roboterassistenten, der einem bei heimischen Bastelarbeiten die richtigen Werkzeuge anreicht, wie man es aus OP-Sälen in Krankenhäusern kennt: „Roboter, Schraubenzieher!“ – „Schraubenzieher, und weiter?“ – „Schraubenzieher, bitte!“
Die Vision: Roboter und Mensch arbeiten zusammen [johanneswienke.de]
Zumindest in Industrieszenarien ist das keine allzu weit entfernte Zukunftsvision mehr. Flexibel anpassbare Roboter, die autonom oder Hand in Hand mit dem Menschen in einer Werkstatt oder Produktionsstrasse arbeiten und diesen bei Fertigungsaufgaben unterstützen, sind schon seit geraumer Zeit ein strategisches Anliegen europäischer Wissenschaftler und der Robotikindustrie. So führt bereits die im Jahr 2009 ausgerufene europäische Strategic Research Agenda diese beiden Szenarien, den „Robotic Worker“ und den „Robotic Co-Worker“, als Kernanwendungsszenarien zukünftiger Industrierobotik mit auf. Dabei geht es nicht um Großserien-Vollautomatisierung wie man sie z. B. aus der Automobilindustrie kennt, in der Roboter an Roboter aufgereiht in Käfigen und – aus Sicherheitsgründen – abgeschottet vom Menschen monatelang exakt die gleiche Aufgabe ausführen:
Vollautmatisierte Montage von Automobilen bei KIA
Es geht vielmehr um die Unterstützung von Mitarbeitern in kleinen und mittelständischen Unternehmen, deren Auftragslage sich relativ schnell ändern kann. Denkbar ist die Fertigung von Prototypen, von denen häufig nur geringe, einstellige Stückzahlen gefertigt werden. In diesem Kontext sind zur Zeit Handarbeitsplätze immer noch die Regel, d. h. Fachkräfte montieren und bearbeiten Bauteile bzw. bestücken und entladen Maschinen manuell. Häufig sind diese Arbeiten verbunden mit anstrengender körperlicher Arbeit.
Eine Vollautomatisierung im klassischen Sinne, also mit Robotern, die genau auf diesen einen Zweck ausgelegt sind und in aller Regel nicht oder nur sehr aufwendig an neue Fertigungsaufgaben angepasst werden können, macht hier allein schon aus ökonomischen Gründen keinen Sinn. Der durch die Einsparung einer Fachkraft gewonnene finanzielle Vorteil wird sofort wieder zunichte gemacht durch den notwendigen, häufigen und kostenintensiven Einsatz von Experten, die den Roboter bei jeder Änderung im Produktionsablauf wieder an seine neue Aufgabe anpassen und umprogrammieren müssen. Zusätzlich sind viele Teilaufgaben in solchen Fertigungsprozessen sehr komplex und wenn überhaupt nur mit enorm hohem technischen Aufwand automatisch zu bewerkstelligen, wie z. B. der berühmte Griff in die Kiste.
Die Idee ist vielmehr, den Menschen zu unterstützen, indem man ihm diejenigen Arbeiten überlässt, die er z. B. auf Grund besserer visueller Wahrnehmung und guten Fingerfertigkeiten kompetenter und schneller durchführen kann als jede Maschine, ihn aber durch den Roboterassistenten von körperlich belastenden Arbeiten zu befreien … der Roboter als dritte Hand. Damit jedoch beide, Roboter und Mensch, an einem Arbeitsplatz gemeinsam sinnvoll zusammenarbeiten können, sind einige Herausforderungen zu bewältigen. Ein bisschen Buzzword-Bingo:
Flexibilität: Um sich den ständig wechselnden Aufgaben anpassen zu können und in beliebigen (engen, eingeschränkten) Arbeitsräumen mit dem Menschen zusammen zu arbeiten, ist im Vergleich zu herkömmlichen Industrierobotern zusätzliche Flexibilität nötig. Diese erhält man z. B. durch zusätzliche Bewegungsachsen: übliche Industrieroboter verfügen über bis zu sechs Achsen, ab sieben Achsen erhält man durch Redundanz zusätzliche Flexibilität.
Interaktion: Um teures und zeitaufwendiges Umprogrammieren der Roboter durch Experten zu umgehen, muss der Mitarbeiter vor Ort in der Lage sein, durch einfache, direkte Interaktion den Roboter an seine neuen Aufgaben und Arbeitsbedingungen anzupassen und ihn den eigenen Bedürfnissen entsprechend zu programmieren. Sicherheit: Die direkte physische Kooperation zwischen Mensch und Maschine erfordert andere Sicherheitsmechanismen als Zäune und strikte Arbeitsraumtrennung, um die Sicherheit für den Menschen dennoch zu gewährleisten.
Technisch gesehen scheinen obige Herausforderungen so gut wie gelöst. Der vom Deutschen Luft- und Raumfahrtszentrum und KUKA gemeinsam entwickelten Leichtbauroboter IV (LBR IV), dessen serienreifer Nachfolger KUKA LBR iiwa auf der diesjährigen Hannover Messe erstmals vorgestellt wurde, ist ein Beispiel. Das geringe Gewicht, Kraftsensoren zur Kollisionserkennung und eine sehr schnelle Regelung sind gute Voraussetzungen für eine sichere Interaktion mit dem Menschen. Außerdem ist der LBR mit seinen sieben Bewegungsachsen redundant, bietet also genügend Flexibilität, um um Hindernisse herumzugreifen oder Aufgaben auf mehr als nur eine Art zu erledigen.
Dass trotzdem nun nicht jeder sofort einem solchen Roboter Aufgaben beibringen kann, sieht man im folgenden Video, welches im Verlaufe einer umfangreichen Feldstudie 4 mit Mitarbeitern der Firma Harting entstand:
https://youtube.com/watch?v=tRTfSWBbE1QAuch moderne Roboter sind nicht leicht zu bedienen.
Die Aufgabe für die Probanden bestand im Prinzip aus einer Art Heißer-Draht-Spiel: Der vorn am Roboter montierte Greifer sollte möglichst genau an dem Styropor-Parcours entlang geführt werden, währenddessen natürlich jede Kollision sowohl vorne am Greifer als auch am Rest des Roboterkörpers mit den Umgebungsobjekten vermieden werden sollte. Der Hintergrund: Genau durch diese Art des Führens (englisch: Kinesthetic Teaching) können dem Roboter Aufgaben beigebracht werden. Die in der Interaktion entstandenen Bewegungen werden aufgezeichnet und können auf Befehl schneller, langsamer oder leicht verändert wieder abgespielt werden. Der Fachbegriff hierfür lautet Teach-In und bezeichnet das aktuell übliche Verfahren, um Roboter „anzulernen“.
Wie man in dem Video sieht, geht das zum Teil gehörig schief! Die Versuchspersonen scheinen (trotz einer vorherigen Eingewöhungsphase mit dem Roboter) überfordert von der Aufgabe, dem LBR den Parcours kollisionsfrei beizubringen. Das liegt nicht an der Komplexität der Aufgabe: Eine einfache vorgegebene dreidimensionale Bewegung wie die des Parcours aus der Studie nachzufahren, ist für uns Menschen typischerweise zu bewältigen und wie wir später sehen werden auch in Verbindung mit einem Roboter leicht möglich. Der Grund ist die durch jahrelange Ingenieurskunst geschaffene, komplizierte Technik des LBR, die technische Vorteile, aber auch erhöhte Komplexität mit sich bringt. Denn hinter dem einen „I“ des Wortes „Interaktion“ verstecken sich noch zwei weitere: intuitiv und intelligent. Einem Roboterarm mit sieben Gelenken eine bestimmte dreidimensionale Bewegung beizubringen und dabei gleichzeitig darauf achten zu müssen, dass er mit seinen sieben Achsen nicht mit Hindernissen im Arbeitsraum kollidiert, ist nicht intuitiv. Und eine vorgemachte Bewegung abspeichern und wieder abspielen zu können, ist nicht sonderlich intelligent.
Dieses Beispiel zeigt, dass in der Praxis mehr notwendig ist als nur die technischen Möglichkeiten zu schaffen. Der Schlüssel, davon sind wir überzeugt, liegt in einer systematischen Integration von Hochtechnologie, maschinellem Lernen und einfacher Interaktion. Um ein solches Robotiksystem für den Arbeiter vor Ort bedienbar zu machen, muss die eigentliche technologische Komplexität im besten Fall hinter intuitiven Benutzerschnittstellen und schrittweiser Interaktion versteckt werden. Am Forschungsinstitut für Kognition und Robotik (CoR-Lab) der Universität Bielefeld beschäftigen wir uns seit Jahren genau damit. Das Robotersystem, das oben im Video zu sehen war und auf einem KUKA LBR IV aufbaut, ist unsere Forschungsplattform FlexIRob: ein Beispielszenario, bei dem wir diese Art von Integration untersuchen. Um die obige Aufgabe zu erleichtern, haben wir einen Ansatz entwickelt, mit dem jeder einen solchen Roboter an neue Umgebungen und Aufgaben anpassen kann. Die Idee ist im Prinzip einfach und beruht darauf, die komplexe Aufgabe in zwei Teilschritte zu unterteilen. Dass das funktioniert, ist im folgenden Video zu sehen:
Erleichterung der Interaktion durch Aufteilung in explizite Konfigurations- und assistierte Programmierphase (ab ca 1:15)
Der erste Teilschritt der Aufgabe heißt Konfigurationsphase und ist unabhängig von der Aufgabe, die der Roboterarm später ausführen soll. In dieser Phase bringt der Nutzer bzw. der Mitarbeiter dem Roboter seine neue Umgebung bei, d. h. eventuelle dauerhafte Hindernisse, welche in seinem Arbeitsbereich platziert sind, wie z. B. herumliegende Objekte, Säulen oder Regale. Als Mensch hat er dabei ein intuitives Verständnis der Szenerie: Er sieht die Hindernisse, er weiß, dass und wie man um sie herumgreifen muss und ist deswegen instinktiv in der Lage, den LBR dabei in ausgesuchte Regionen zu führen und dort mit ihm zusammen einige Beispielbewegungen durchzuführen, ohne mit den Hindernissen zu kollidieren. Von diesen Beispielbewegungen kann nun der Roboterarm lernen, wie er sich in seinem Arbeitsbereich zu bewegen und wie er die Hindernisse im Zweifel zu umgreifen hat. Die Methoden zum Lernen, die dabei verwendet werden, gehen über simples Aufnehmen und Reproduzieren hinaus. Mit Hilfe von künstlichen neuronalen Netzen ist das System nämlich nicht nur in der Lage sich innerhalb der trainierten Bereiche zu bewegen, sondern auch zwischen diesen hin- und her zu manövrieren und kollisionsfreie Bewegungen für den Arm zu wählen. Diese Eigenschaft von Lernverfahren nennt man Generalisierungsfähigkeit und beschreibt die Fähigkeit, von wenigen Beispieldaten ein generelles Verhalten zu erlernen und dieses auf unbekannte Daten zu übertragen. In unserem Fall sind die Beispieldaten die Trainingsdaten, welche vom Nutzer zur Verfügung gestellt werden und im Video als grüne Punkte dargestell sind. Von diesen lernt der Roboter innerhalb weniger Minuten, beliebige Zielpositionen anzufahren, ohne dabei mit den Hindernissen zu kollidieren. Und das nicht nur in den Trainingsbereichen, sondern auch darüber hinaus 5.
Im nächsten Schritt, geht es nun darum, ihm die eigentliche Aufgabe beizubringen. Das kann z. B. eine Schweiß- oder Klebenaht sein und auf verschiedenen Wegen passieren, z. B. erneut mit Hilfe von Kinesthetic Teaching, also dem direkten Führen des Roboters. Da dieser sich aber in seiner Umgebung nun schon zu bewegen weiß, braucht der Nutzer nicht mehr alle Gelenke gleichzeitig zu kontrollieren. Es reicht, dass er ihn vorn am Greifer entlang der spezifischen Aufgabe führt und der Roboter assistiert ihm dabei sozusagen bei der Hindernisvermeidung, wie in dem Video ab Minute 2:10 zu sehen ist. Diese Phase nennen wir deshalb Assisted Programming.
Der Knackpunkt zur Vereinfachung dieser Interaktion liegt also in der Aufteilung der Gesamtaufgabe in zwei oder mehr aufeinander aufbauende Teilschritte, um den Nutzer bzw. Mitarbeiter des Roboters nicht zu überfordern. Im letzten Jahr haben wir mit Unterstützung der Firma Harting oben genannte Pilotstudie zum Thema Kinesthetic Teaching durchgeführt und die beschriebene Idee evaluiert. Dabei haben 48 Mitarbeiter, unterteilt in zwei Versuchsgruppen, mit dem System interagiert und versucht, dem Roboter obigen Parcours beizubringen. Die Ergebnisse der einen Gruppe waren bereits im ersten Video zu sehen. Von 24 Versuchsteilnehmern, haben es gerade einmal zwei Probanden geschafft, den Parcours kollisionsfrei abzufahren; eine Probandin brach ihren Versuch nach einiger Zeit frustriert ab. Die zweite Versuchsgruppe hingegen benutzte den assistierten Modus und zeigte signifikant bessere Ergebnisse. Diese Teilnehmer benötigten im Schnitt weniger als die Hälfte der Zeit, um den Roboter anzulernen, die beigebrachten Bewegungen waren signifikant näher an der Vorgabe und wesentlich ruckelfreier.
Unsere Experimente und Studien legen nahe, dass moderne Robotiksysteme durchaus über die Flexibilität verfügen, regelmäßig und vor Ort an wechselnde Aufgaben angepasst zu werden, wie es zum Beispiel für Kleinserienfertigung oder Prototypenbau notwendig ist. Dazu reicht die rein technische Flexibilität allerdings nicht aus, denn sie erfordert immer noch lange Einarbeitung und Robotikexperten. Erst in der Kombination mit lernenden Systemen und einfachen Interaktionsschnittstellen spielen solche Systeme ihr volles Potential aus.
Christian Emmerich und Arne Nordmannsind Doktoranden am Forschungsinstitut für Kognition und Robotik der Universität Bielefeld und beschäftigen sich mit lernenden, interaktiven Robotiksystemen.
Diese Woche hat 3sat eine Themenwoche „Die Macht der Maschinen“ mit vielen Spielfilmen und Dokumentationen zur vielen unterschiedlichen, gesellschaftlichen Aspekten der Robotik.
Gestern zum Beispiel mit Dokumentation zu unbemannten Drohnen, Roboter für medizinische Operationen und Pflege, etc. Die ganze Woche geht es noch spannend weiter.