Nachdem IBMs Deep Blue schon vor mittlerweile 20 Jahren den Schach-Großmeister Gary Kasparov geschlagen hat, galt das chinesische Brettspiel Go als die nächste große Herausforderung für künstliche Intelligenz. Go-Großmeister zu schlagen, progostizierte man noch bis vor einem Jahr, würde noch mindestens 10 Jahre dauern. Nachdem AlphaGo, die künstliche Intelligenz von Google für das Spielen von Go im Januar schon Fan Hui, den Go-Europameister, geschlagen hat, musste sich nun auch der Koreaner Lee Sedol, einer der weltbesten Go-Spieler, 3:0 geschlagen geben.
Wie schon der Sieg im Schach, wird dies vielfach als weiterer Meilenstein der künstlichen Intelligenz gefeiert. Aber ist es das? Ist es ein Meilenstein oder durch die stetig wachsende Rechenpower und mehr Effizienz beim machinellen Lernen zu erklären?
AlphaGo
AlphaGo wurde mit Millionen von Go-Spielen trainiert, von denen AlphaGo lernen konnte, welche Züge erfolgversprechend sind und zum Sieg führen. Darauf aufbauend spielte AlphaGo mehrere Millionen Spiele gegen sich selbst und sammelte so immer mehr Erfahrung. Als AlphaGo jetzt also gegen Lee Sedol spielte, hatte es viele Millionen Spiele gespielt, mehr als ein einzelner Mensch in seiner gesamten Lebenszeit spielen könnte. Ist es dann also besser als ein Mensch?
Schlaue Menschen sprechen in diesem Kontext von Daten-Effizienz: also wieviele Daten, in diesem Fall Erfahrung von vergangenen Go-Spielen, benötigt werden, um etwas zu erlernen. Während AlphaGo also um Größenordnungen mehr Spiele spielen musste, hat Lee Sedol das Spiel aus sehr viel weniger Erfahrung beherrschen gelernt.
Google hat mit AlphaGo eine beeindruckende Leistung abgeliefert, vor der der Hut zu ziehen ist. Besser Go spielen lernen als der Mensch kann AlphaGo deswegen aber lange noch nicht.
Wer hat sich nicht schon einmal einen Roboter gewünscht, der im Haushalt hilft? Der zum Beispiel schon einmal den Kuchenteig anrührt, knetet und ausrollt, während man selbst die Glasur vorbereitet, bzw. einem das lästige Gemüseschnibbeln beim Kochen abnimmt. Oder einen kleinen Roboterassistenten, der einem bei heimischen Bastelarbeiten die richtigen Werkzeuge anreicht, wie man es aus OP-Sälen in Krankenhäusern kennt: „Roboter, Schraubenzieher!“ – „Schraubenzieher, und weiter?“ – „Schraubenzieher, bitte!“
Die Vision: Roboter und Mensch arbeiten zusammen [johanneswienke.de]
Zumindest in Industrieszenarien ist das keine allzu weit entfernte Zukunftsvision mehr. Flexibel anpassbare Roboter, die autonom oder Hand in Hand mit dem Menschen in einer Werkstatt oder Produktionsstrasse arbeiten und diesen bei Fertigungsaufgaben unterstützen, sind schon seit geraumer Zeit ein strategisches Anliegen europäischer Wissenschaftler und der Robotikindustrie. So führt bereits die im Jahr 2009 ausgerufene europäische Strategic Research Agenda diese beiden Szenarien, den „Robotic Worker“ und den „Robotic Co-Worker“, als Kernanwendungsszenarien zukünftiger Industrierobotik mit auf. Dabei geht es nicht um Großserien-Vollautomatisierung wie man sie z. B. aus der Automobilindustrie kennt, in der Roboter an Roboter aufgereiht in Käfigen und – aus Sicherheitsgründen – abgeschottet vom Menschen monatelang exakt die gleiche Aufgabe ausführen:
Vollautmatisierte Montage von Automobilen bei KIA
Es geht vielmehr um die Unterstützung von Mitarbeitern in kleinen und mittelständischen Unternehmen, deren Auftragslage sich relativ schnell ändern kann. Denkbar ist die Fertigung von Prototypen, von denen häufig nur geringe, einstellige Stückzahlen gefertigt werden. In diesem Kontext sind zur Zeit Handarbeitsplätze immer noch die Regel, d. h. Fachkräfte montieren und bearbeiten Bauteile bzw. bestücken und entladen Maschinen manuell. Häufig sind diese Arbeiten verbunden mit anstrengender körperlicher Arbeit.
Eine Vollautomatisierung im klassischen Sinne, also mit Robotern, die genau auf diesen einen Zweck ausgelegt sind und in aller Regel nicht oder nur sehr aufwendig an neue Fertigungsaufgaben angepasst werden können, macht hier allein schon aus ökonomischen Gründen keinen Sinn. Der durch die Einsparung einer Fachkraft gewonnene finanzielle Vorteil wird sofort wieder zunichte gemacht durch den notwendigen, häufigen und kostenintensiven Einsatz von Experten, die den Roboter bei jeder Änderung im Produktionsablauf wieder an seine neue Aufgabe anpassen und umprogrammieren müssen. Zusätzlich sind viele Teilaufgaben in solchen Fertigungsprozessen sehr komplex und wenn überhaupt nur mit enorm hohem technischen Aufwand automatisch zu bewerkstelligen, wie z. B. der berühmte Griff in die Kiste.
Die Idee ist vielmehr, den Menschen zu unterstützen, indem man ihm diejenigen Arbeiten überlässt, die er z. B. auf Grund besserer visueller Wahrnehmung und guten Fingerfertigkeiten kompetenter und schneller durchführen kann als jede Maschine, ihn aber durch den Roboterassistenten von körperlich belastenden Arbeiten zu befreien … der Roboter als dritte Hand. Damit jedoch beide, Roboter und Mensch, an einem Arbeitsplatz gemeinsam sinnvoll zusammenarbeiten können, sind einige Herausforderungen zu bewältigen. Ein bisschen Buzzword-Bingo:
Flexibilität: Um sich den ständig wechselnden Aufgaben anpassen zu können und in beliebigen (engen, eingeschränkten) Arbeitsräumen mit dem Menschen zusammen zu arbeiten, ist im Vergleich zu herkömmlichen Industrierobotern zusätzliche Flexibilität nötig. Diese erhält man z. B. durch zusätzliche Bewegungsachsen: übliche Industrieroboter verfügen über bis zu sechs Achsen, ab sieben Achsen erhält man durch Redundanz zusätzliche Flexibilität.
Interaktion: Um teures und zeitaufwendiges Umprogrammieren der Roboter durch Experten zu umgehen, muss der Mitarbeiter vor Ort in der Lage sein, durch einfache, direkte Interaktion den Roboter an seine neuen Aufgaben und Arbeitsbedingungen anzupassen und ihn den eigenen Bedürfnissen entsprechend zu programmieren. Sicherheit: Die direkte physische Kooperation zwischen Mensch und Maschine erfordert andere Sicherheitsmechanismen als Zäune und strikte Arbeitsraumtrennung, um die Sicherheit für den Menschen dennoch zu gewährleisten.
Technisch gesehen scheinen obige Herausforderungen so gut wie gelöst. Der vom Deutschen Luft- und Raumfahrtszentrum und KUKA gemeinsam entwickelten Leichtbauroboter IV (LBR IV), dessen serienreifer Nachfolger KUKA LBR iiwa auf der diesjährigen Hannover Messe erstmals vorgestellt wurde, ist ein Beispiel. Das geringe Gewicht, Kraftsensoren zur Kollisionserkennung und eine sehr schnelle Regelung sind gute Voraussetzungen für eine sichere Interaktion mit dem Menschen. Außerdem ist der LBR mit seinen sieben Bewegungsachsen redundant, bietet also genügend Flexibilität, um um Hindernisse herumzugreifen oder Aufgaben auf mehr als nur eine Art zu erledigen.
Dass trotzdem nun nicht jeder sofort einem solchen Roboter Aufgaben beibringen kann, sieht man im folgenden Video, welches im Verlaufe einer umfangreichen Feldstudie 1 mit Mitarbeitern der Firma Harting entstand:
Auch moderne Roboter sind nicht leicht zu bedienen.
Die Aufgabe für die Probanden bestand im Prinzip aus einer Art Heißer-Draht-Spiel: Der vorn am Roboter montierte Greifer sollte möglichst genau an dem Styropor-Parcours entlang geführt werden, währenddessen natürlich jede Kollision sowohl vorne am Greifer als auch am Rest des Roboterkörpers mit den Umgebungsobjekten vermieden werden sollte. Der Hintergrund: Genau durch diese Art des Führens (englisch: Kinesthetic Teaching) können dem Roboter Aufgaben beigebracht werden. Die in der Interaktion entstandenen Bewegungen werden aufgezeichnet und können auf Befehl schneller, langsamer oder leicht verändert wieder abgespielt werden. Der Fachbegriff hierfür lautet Teach-In und bezeichnet das aktuell übliche Verfahren, um Roboter „anzulernen“.
Wie man in dem Video sieht, geht das zum Teil gehörig schief! Die Versuchspersonen scheinen (trotz einer vorherigen Eingewöhungsphase mit dem Roboter) überfordert von der Aufgabe, dem LBR den Parcours kollisionsfrei beizubringen. Das liegt nicht an der Komplexität der Aufgabe: Eine einfache vorgegebene dreidimensionale Bewegung wie die des Parcours aus der Studie nachzufahren, ist für uns Menschen typischerweise zu bewältigen und wie wir später sehen werden auch in Verbindung mit einem Roboter leicht möglich. Der Grund ist die durch jahrelange Ingenieurskunst geschaffene, komplizierte Technik des LBR, die technische Vorteile, aber auch erhöhte Komplexität mit sich bringt. Denn hinter dem einen „I“ des Wortes „Interaktion“ verstecken sich noch zwei weitere: intuitiv und intelligent. Einem Roboterarm mit sieben Gelenken eine bestimmte dreidimensionale Bewegung beizubringen und dabei gleichzeitig darauf achten zu müssen, dass er mit seinen sieben Achsen nicht mit Hindernissen im Arbeitsraum kollidiert, ist nicht intuitiv. Und eine vorgemachte Bewegung abspeichern und wieder abspielen zu können, ist nicht sonderlich intelligent.
Dieses Beispiel zeigt, dass in der Praxis mehr notwendig ist als nur die technischen Möglichkeiten zu schaffen. Der Schlüssel, davon sind wir überzeugt, liegt in einer systematischen Integration von Hochtechnologie, maschinellem Lernen und einfacher Interaktion. Um ein solches Robotiksystem für den Arbeiter vor Ort bedienbar zu machen, muss die eigentliche technologische Komplexität im besten Fall hinter intuitiven Benutzerschnittstellen und schrittweiser Interaktion versteckt werden. Am Forschungsinstitut für Kognition und Robotik (CoR-Lab) der Universität Bielefeld beschäftigen wir uns seit Jahren genau damit. Das Robotersystem, das oben im Video zu sehen war und auf einem KUKA LBR IV aufbaut, ist unsere Forschungsplattform FlexIRob: ein Beispielszenario, bei dem wir diese Art von Integration untersuchen. Um die obige Aufgabe zu erleichtern, haben wir einen Ansatz entwickelt, mit dem jeder einen solchen Roboter an neue Umgebungen und Aufgaben anpassen kann. Die Idee ist im Prinzip einfach und beruht darauf, die komplexe Aufgabe in zwei Teilschritte zu unterteilen. Dass das funktioniert, ist im folgenden Video zu sehen:
Erleichterung der Interaktion durch Aufteilung in explizite Konfigurations- und assistierte Programmierphase (ab ca 1:15)
Der erste Teilschritt der Aufgabe heißt Konfigurationsphase und ist unabhängig von der Aufgabe, die der Roboterarm später ausführen soll. In dieser Phase bringt der Nutzer bzw. der Mitarbeiter dem Roboter seine neue Umgebung bei, d. h. eventuelle dauerhafte Hindernisse, welche in seinem Arbeitsbereich platziert sind, wie z. B. herumliegende Objekte, Säulen oder Regale. Als Mensch hat er dabei ein intuitives Verständnis der Szenerie: Er sieht die Hindernisse, er weiß, dass und wie man um sie herumgreifen muss und ist deswegen instinktiv in der Lage, den LBR dabei in ausgesuchte Regionen zu führen und dort mit ihm zusammen einige Beispielbewegungen durchzuführen, ohne mit den Hindernissen zu kollidieren. Von diesen Beispielbewegungen kann nun der Roboterarm lernen, wie er sich in seinem Arbeitsbereich zu bewegen und wie er die Hindernisse im Zweifel zu umgreifen hat. Die Methoden zum Lernen, die dabei verwendet werden, gehen über simples Aufnehmen und Reproduzieren hinaus. Mit Hilfe von künstlichen neuronalen Netzen ist das System nämlich nicht nur in der Lage sich innerhalb der trainierten Bereiche zu bewegen, sondern auch zwischen diesen hin- und her zu manövrieren und kollisionsfreie Bewegungen für den Arm zu wählen. Diese Eigenschaft von Lernverfahren nennt man Generalisierungsfähigkeit und beschreibt die Fähigkeit, von wenigen Beispieldaten ein generelles Verhalten zu erlernen und dieses auf unbekannte Daten zu übertragen. In unserem Fall sind die Beispieldaten die Trainingsdaten, welche vom Nutzer zur Verfügung gestellt werden und im Video als grüne Punkte dargestell sind. Von diesen lernt der Roboter innerhalb weniger Minuten, beliebige Zielpositionen anzufahren, ohne dabei mit den Hindernissen zu kollidieren. Und das nicht nur in den Trainingsbereichen, sondern auch darüber hinaus 2.
Im nächsten Schritt, geht es nun darum, ihm die eigentliche Aufgabe beizubringen. Das kann z. B. eine Schweiß- oder Klebenaht sein und auf verschiedenen Wegen passieren, z. B. erneut mit Hilfe von Kinesthetic Teaching, also dem direkten Führen des Roboters. Da dieser sich aber in seiner Umgebung nun schon zu bewegen weiß, braucht der Nutzer nicht mehr alle Gelenke gleichzeitig zu kontrollieren. Es reicht, dass er ihn vorn am Greifer entlang der spezifischen Aufgabe führt und der Roboter assistiert ihm dabei sozusagen bei der Hindernisvermeidung, wie in dem Video ab Minute 2:10 zu sehen ist. Diese Phase nennen wir deshalb Assisted Programming.
Der Knackpunkt zur Vereinfachung dieser Interaktion liegt also in der Aufteilung der Gesamtaufgabe in zwei oder mehr aufeinander aufbauende Teilschritte, um den Nutzer bzw. Mitarbeiter des Roboters nicht zu überfordern. Im letzten Jahr haben wir mit Unterstützung der Firma Harting oben genannte Pilotstudie zum Thema Kinesthetic Teaching durchgeführt und die beschriebene Idee evaluiert. Dabei haben 48 Mitarbeiter, unterteilt in zwei Versuchsgruppen, mit dem System interagiert und versucht, dem Roboter obigen Parcours beizubringen. Die Ergebnisse der einen Gruppe waren bereits im ersten Video zu sehen. Von 24 Versuchsteilnehmern, haben es gerade einmal zwei Probanden geschafft, den Parcours kollisionsfrei abzufahren; eine Probandin brach ihren Versuch nach einiger Zeit frustriert ab. Die zweite Versuchsgruppe hingegen benutzte den assistierten Modus und zeigte signifikant bessere Ergebnisse. Diese Teilnehmer benötigten im Schnitt weniger als die Hälfte der Zeit, um den Roboter anzulernen, die beigebrachten Bewegungen waren signifikant näher an der Vorgabe und wesentlich ruckelfreier.
Unsere Experimente und Studien legen nahe, dass moderne Robotiksysteme durchaus über die Flexibilität verfügen, regelmäßig und vor Ort an wechselnde Aufgaben angepasst zu werden, wie es zum Beispiel für Kleinserienfertigung oder Prototypenbau notwendig ist. Dazu reicht die rein technische Flexibilität allerdings nicht aus, denn sie erfordert immer noch lange Einarbeitung und Robotikexperten. Erst in der Kombination mit lernenden Systemen und einfachen Interaktionsschnittstellen spielen solche Systeme ihr volles Potential aus.
Christian Emmerich und Arne Nordmannsind Doktoranden am Forschungsinstitut für Kognition und Robotik der Universität Bielefeld und beschäftigen sich mit lernenden, interaktiven Robotiksystemen.
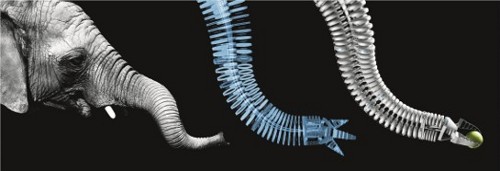
Festos Bionic Handling Assistent (BHA), inspiriert von einem Elefantenrüssel
Schon vor gut einem Jahr habe ich über Festos Bionic Handling Assistent (BHA) geschrieben, der damals frisch mit dem Deutschen Zukunftspreis gekrönt war. Wir haben einen von diesen Robotern bekommen und im April letzten Jahres haben wir bereits hier über unsere ersten Gehversuche und die Simulation des Roboters geschrieben. In diesem Artikel wird es nun darum gehen, wie wir von Babys gelernt haben, den Roboter zu kontrollieren.
Vor einigen Wochen wurde der BHA in der Sendung mit der Maus gezeigt. Wer das Video bis zu Minute 5:00 verfolgt, bekommt jedoch den Haken mit: so faszinierend der Roboter, insbesondere der BHA, auch ist … es ist ebenso kompliziert, ihn zu bewegen.
Die Sendung mit der Maus – Festos BHA und Robotino
In der Sendung und bei den meisten Vorführungen des Roboters steht daher jemand an einer Fernbedienung, oder öffnet und schließt händisch die Ventile, wie zu Beginn des Videos zu sehen. Von einem praktischen Einsatz, bei dem der Roboter eigenständig Aufgaben erledigt, ist das noch meilenweit entfernt.
Das liegt unter anderem daran, dass der Rüssel anders ist, als andere Roboter. Seine elastischen Bewegungen sind sehr schwierig und nur annähernd in mathematische Gleichungen zu fassen. Genau diese Bewegungsgleichungen benötigen aber die klassische Verfahren zur Robotersteuerung. Selbst unser Modell reicht dazu kaum aus, denn es kann keine Auskunft über die Reichweite der vielen Aktuatoren liefern. Diese müsste man sehr genau kennen um den Roboter (klassisch) ansteuern zu können: es ergeben sich schnell sehr große Fehler, wenn der Regler einem Aktuator einen Befehl gibt, der außerhalb seiner Reichweite liegt.
Was das Ganze noch schwieriger macht sind die Verzögerungen im Bewegungsverhalten: der Roboter bewegt sich mittels Luftkammern, die mit Druckluft aufgeblasen werden, die aber erst mit Verzögerung in den Kammern ankommt. Danach dauert es einige Zeit, mitunter bis zu 20 Sekunden, bis der Roboter seine neue Postur erreicht und sich stabilisiert hat. Diese Verzögerungen machen viele der sonst auf Robotern verwendeten Regler praktisch nutzlos, da sie schnelles und exaktes Roboterverhalten benötigen.
Schwierig … aber dafür gibt es maschinelle Lernverfahren, von denen es unzählige Methoden gibt, um Roboter Bewegungen lernen zu lassen. Zunächst muss man den Roboter seinen Bewegungsraum explorieren lassen, also ausprobieren welche resultierenden Bewegungen durch verschiedene Motorkommandos hervorgerufen werden. Da liegt allerdings schon die nächste Krux mit dem BHA, denn: es gibt sehr, sehr viele verschiedene Motorkommandos. Die Standard-Ansätze zum Lernen erfordern, sie alle auszuprobieren. Auf dem BHA benutzen wir aktuell neun Aktuatoren (die Luftkammern). Möchte man pro Aktuator nur 10 verschiedene Kommandos ausprobieren, ergeben sich bereits eine Milliarde (10^9) Kombinationen. Es würde Jahrzehnte dauern, würde man ernsthaft versuchen die alle auf dem Roboter zu explorieren. In der Praxis würde man daher eher zufällige Kommandos auswählen, und einfach irgendwann aufhören. Natürlich ändert das aber auch nichts daran, dass man eigentlich alle Kommandos ausprobieren müsste, damit das Bewegungslernen funktionieren kann.
Was tun?
Um diesem Problem zu begegnen, haben wir uns Inspiration aus der Biologie geholt. Die Aufgabe, den BHA-Rüssel kontrollieren zu lernen, ist nämlich in vielerlei Hinsicht der Aufgabe von Babys sehr ähnlich, in den ersten Lebensmonaten zu lernen, ihre eigenen Gliedmaßen zielgerichtet zu bewegen. Sie müssen dafür lernen, 600 Muskeln zu koordinieren, und sind dabei unglaublich effizient. Was ist also der Trick, den wir lernen müssen, wenn wir unsere Experimente mit dem BHA ähnlich effizient durchführen wollen?
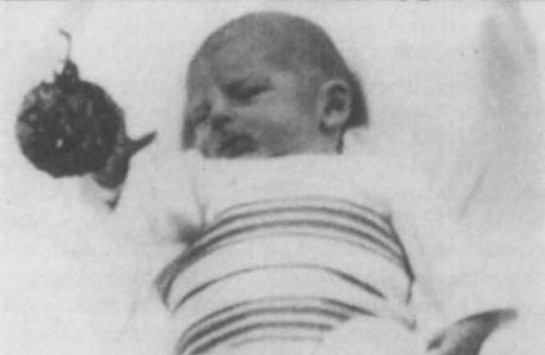
Einen Hinweis liefert eine wegweisende Studie von Claes von Hosten aus dem Jahr 1982. Diese Studie konnte zeigen, dass selbst Neugeborene sich nicht ‐ wie es zuerst scheint ‐ zufällig bewegen, sondern von Beginn an zielgerichtet in Richtung bewegter Objekte greifen. Das folgende Bild zeigt dies unglaublicherweise bereits bei einem wenige Tage alten Baby:
Ein wenige Tage altes Neugeborenes zeigt bereits zielgerichtete Bewegung Richtung bewegter Objekte
Diese Erkenntnis wurde lange von der Machine Learning Community ignoriert, und sollte uns den entscheidenden Hinweis geben. Der von Matthias Rolf entwickelte Ansatz Goal Babbling, versucht nicht mehr durch zufällige Bewegungen den Bewegungsraum zu explorieren (Motor Babbling), sondern tut es von Anfang an zielgerichtet [Rolf et al., 2011]. Die Ergebnisse in Simulation waren vielversprechend, und haben gezeigt, dass dieser Ansatz auch mit 50 Freiheitsgraden zurecht kommt und nicht einmal mehr Zeit benötigt als für einen Roboter mit nur zwei Gelenken. Das ist ein entscheidender Vorteil gegenüber dem zufälligen Explorieren des Raumes, dessen Zeit zum Explorieren exponentiell mit der Anzahl der Dimensionen steigt. Mit Goal Babbling erhalten wir erste brauchbare Resultate bereits nach wenigen hundert Bewegungen, was sogar mit der Geschwindigkeit menschlichen Lernens vergleichbar ist [Sailer and Flanagan, 2005]. Wir können also offenbar wirklich mit der biologischen Vorlage das Lernen massiv beschleunigen! Zeit also, das biologisch-inspirierte Lernen auf dem biologisch inspirierten Roboter anzuwenden.
In unseren ersten Experimenten lernte der Roboter lediglich einfache Bewegungen des Greifers nach links und rechts. Nicht besonders nützlich, aber trotzdem beeindruckend als Live-Demonstration, denn der Roboter konnte innerhalb von zwei Minuten eigenständig lernen, seine neun Kammern zu koordinieren und diese Bewegung auszuführen. Schnell zeigte sich außerdem, wie gut das Verfahren mit Hardware-Defekten umgehen konnte, obwohl wir wahrlich nicht vor hatten, das herauszufinden. Eines Tages während der Experimente stellten wir jedoch ein kleines Loch in einer der Luftkammern fest, durch das Luft entwich: die Kammer konnte sich nicht mehr aufblasen. Schlimmer noch: die Kammer bewegte sich passiv wie eine mechanische Feder mit, was die Bewegung des gesamten BHA-Rüssels beeinflusste. Das Lernverfahren scherte das kaum. Es lernte einfach die anderen Aktuatoren entsprechend einzusetzen ‐ zusammen mit der passiven Bewegung des defekten Aktuators. Wohlgemerkt: wir mussten dem Verfahren dafür nicht mitteilen, dass etwas defekt war. So einfach kann es manchmal sein!
Eine ähnlich gute Entdeckung machten wir, als jemand den Roboter hin und her schob, während er grade explorierte und lernte. Durch das Anschubsen des Roboters konnte man ihm tatsächlich unter die Arme greifen und ihm zeigen, wie sinnvolle Bewegungen aussehen. Schiebt man ihn in die Richtung, in die er sich gerade bewegen will (also die richtige Richtung), spürt man bemerkenswerterweise kaum Widerstand vom Regler. Das Lernen geschieht in diesen Momenten so schnell, das der Roboter die Bewegung schon während des Führens in den gelernten Regler einarbeitet. Folglich reicht es aus, ihm die Bewegung ein einziges mal zu zeigen. Das Ganze ist überhaupt nur möglich, weil das ziel-gerichtete Explorieren und sehr schnelles kontinuierliches Lernen des Goal Babblings mit dem leichten, nachgiebigen BHA-Rüssel aufeinander treffen. Preis-gekrönte 1, biologisch inspirierte Hardware und preis-gekröntes 2, biologisch inspiriertes Lernen.
Bei dem gesamten Vorhaben leistete uns die vorher entwickelte Simulation des Bewegungsverhaltens gute Dienste. Auch wenn das Lernen und Explorieren auf dem echten Roboter stattfand, war die Simulation für allerhand Visualisierungen und zusätzliche Vorhersagen nützlich. So ließ sich nun die Bewegung des Roboters bezüglich selbst-generierter (und ausschließlich virtuell existierender) Ziele während des Lernens darstellen, und das Lernen auf dreidimensionale Ziele (anstatt nur links/rechts) erweitern. Wir konnten nun Einblick in das Lernen nehmen und live während des Lernens vorhersagen, wie gut der gerade lernende Regler verschiedene Positionen im Raum anfahren kann. Wir lernten dadurch, dass sich das Lernen auf dem echten Roboter ganz ähnlich entfaltet wie es unsere ersten Simulations-Experimenten 2010 bis Anfang 2011 (noch komplett ohne den BHA) gezeigt haben.
Biologisch inspiriertes Lernen auf einem biologisch inspirierten Roboter
Auf dem Rüssel liefert Goal Babbling schnell nützliche Ergebnisse. Nach dem Lernen lässt sich der Greifer mit ca. 2 cm Genauigkeit im Raum positionieren. Das ist nicht direkt perfekt, aber reicht in vielen Fällen schon aus, da der flexible Fin-Gripper Gegenstände großräumig mit seinen elastischen Fingern umschließt. Um den Rüssel so schnell und gezielt wie im Video bewegen zu können, darf man nicht auf Feedback (also Bewegungsantworten) vom Roboter warten, da das bei der Pneumatik zu lange dauert. Solch einen Regler, der ohne Feedback auskommt, liefert uns das Lernen. Dadurch weiß der Roboter sofort, wo er hin muss, anstatt sich langsam und Schritt für Schritt ans Ziel heranzutasten. Feedback ist dann lediglich eine zusätzliche Hilfe, die wie in der letzten Sequenz im Video zu sehen, die Genauigkeiten auf 6-8 mm erhöht. In Anbetracht der Tatsache, dass der Rüssel selbst permanent ca. 5 mm hin- und herschwankt, ist das beachtlich.
Erwähnenswert ist außerdem: das Ganze funktioniert nicht nur einmalig und im Video. Wir haben sehr ausgiebige Experimente dazu gemacht, und es funktionierte in jedem Durchgang. Das Lernen von links-/rechts-Bewegungen haben wir regelmäßig in Live-Demos gezeigt, in denen der Roboter binnen 1-3 Minuten seine Bewegungen lernt. Unter Anderem haben wir dies live auf der Automatica 2012 in München gezeigt, auf der das Live-Lernen mit dem Roboter und dem Objekt-Tracking aus dem Video vier Tage lang jeweils acht Stunden lief.
Die gute Nachricht lautet also: es funktioniert! Und es funktioniert robust!
Festos Bionic Handling Assistant ist ein großartiger, spannender Roboter. Er ist nicht nur ein Hingucker durch seine Ähnlichkeit mit dem Elefantenrüssel, sondern seine Struktur macht auch den Umgang und die Interaktion mit ihm natürlich und sicher. Um ihn allerdings auf ähnliche Art und Weise kontrollieren zu können, wie wir es mit anderen Robotern tun, mussten wir einige Hürden überwinden: Ausgangspunkt war ein Roboter ganz ohne Modell und nur mit einfacher Druckregelung. Stück für Stück haben wir ein Vorwärtsmodell der Kinematik, Simulation und Längenregelung hinzugefügt. Der entscheidende Punkt war allerdings, maschinelles Lernen, vor Allem das durch Beobachtung von Babys inspirierte Goal Babbling einzusetzen, das erstaunlich schnell lernt, den Roboter zu kontrollieren.
Jetzt, da wir den Rüssel kontrollieren können, um Objekte zu greifen und zu bewegen: Für welche Aufgaben sollten wir ihn jetzt unbedingt einsetzen?
Im April 2010 wurde der Bionische Handling-Assistent (BHA) von Festo auf der Hannover Messe der Öffentlichkeit vorgestellt. In den folgenden Monaten sah dieser biologisch inspirierte Roboterarm zu recht eine große Medienpräsenz und wurde mit zahlreichen Preisen, unter anderem dem Deutschen Forschungspreis 2010, ausgezeichnet. Im Februar 2011 bekamen wir dann unseren eigenen BHA, voller Vorfreude, denn wir wussten, dass niemand bislang mit dem BHA tun konnte, was wir mit ihm vorhatten: ihn zu kontrollieren.1
Die Struktur und Funktionsweise des BHA ist inspiriert von einem Elefantenrüssel, wie in folgender Abbildung unschwer zu erkennen ist. Der Arm wird im Sinne des Rapid Prototypings im 3D-Drucker gedruckt. Als Material wird Polyamid verwendet, wodurch der gesamte Arm leicht-gewichtig und durchgängig verformbar wird: Im Wesentlichen besteht der BHA also aus Plastik und einer Menge Luft. Bewegt wird der Arm von dreizehn pneumatischen Ventilen, die die dreizehn Kammern des Roboters mit Luft füllen oder entleeren. Dies wiederum verbiegt, beugt und streckt die komplette Struktur.
Von einem Elefantenrüssel inspiriert
Festo hat mit dem BHA die Vision eines leichten, freibeweglichen Dritte-Hand-Systems, das den Menschen bei seiner Arbeit unterstützen kann. Dank seiner strukturellen Nachgiebigkeit (Compliance) ist der Arm im Kontakt mit Menschen und seiner Umgebung naturgemäß sicher, was die Möglichkeiten von direkter Zusammenarbeit von Mensch und Roboter eröffnet. In industriellem Kontext kann der BHA in Fertigungsprozessen eingesetzt werden, z.B. um mit empfindlichen Gütern wie z.B. Lebensmitteln zu arbeiten.
Als wir uns entschlossen haben, Festos Bionischen Handling-Assistenten zu erwerben, wussten wir, dass wenige der klassischen und bekannten Verfahren mit diesem Roboter funktionieren würden. Trotzdem war überraschend, dass der Roboter ohne jegliche Software ausgeliefert wurde.
Keine Software.
Nichts.
Noch bis vor einem Jahr konnten wir mit dem BHA nicht viel mehr tun, als von Hand die pneumatischen Ventile zu öffnen und zu schließen, um damit entweder vollen Druck oder gar keinen Druck in die Kammern zu geben. Auch damit waren die Bewegungen des Roboters absolut faszinierend und wir hatten großen Spaß, aber ernsthafte Anwendungen waren damit natürlich noch nicht möglich. Wie von Festo zugesagt, bekamen wir dann vor fast genau einem Jahr elektronische Ventile, mit denen wir (mehr oder weniger präzise) den Druck in den Kammern automatisch vorgeben konnten. Nicht mehr und nicht weniger: den Druck kontrollieren.
Um es einmal vorsichtig zu sagen: Der Schritt von dieser Druckregelung zu einer ernsthaften Anwendung mit dem BHA ist groß!
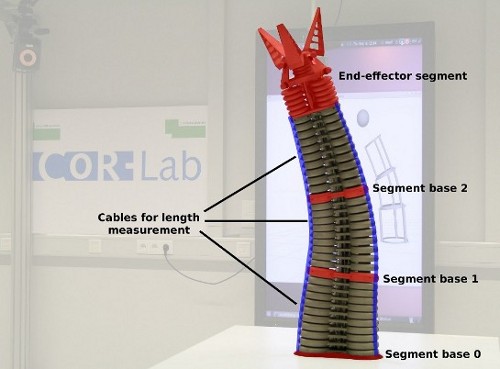
Das tatsächliche Werkzeug, dass man mit dem BHA kontrollieren will, ist der sogenannte Fin Gripper am Ende des Arms. Diesen Greifer zu allerdings genau zu positionieren setzt zuallererst voraus, die Postur des Arms präzise bestimmen zu können. Den Druck in den einzelnen Kammern zu kennen, reicht dafür bei weitem nicht aus; dass dies zum Scheitern verurteilt sein würde, diese Erfahrung hatten wir bereits mir anderen Robotikplattformen gemacht: Zehn Mal den gleichen Druck auf einen pneumatischen Roboter zu geben, ergibt im Regelfall zehn verschiedene Posturen des Roboters. Reibung, Reibung, Hysterese-Effekte und Nicht-Stationaritäten verändern das Ergebnis von Mal zu Mal.
Die kinematische Struktur des BHA
Um diesen Problemen zu begegnen, besitzt der BHA Längensensoren (Kabel-Potentiometer), um an der Außenseite des Arms die Streckung der einzelnen Kammern zu messen (siehe obige Abbildung). Natürlich wollten wir diese Länge nicht nur kennen, sondern auch kontrollieren können. Das ist theoretisch mit klassischer (PID-)Regeltechnik möglich, aber funktioniert auf diese Weise nur sehr schlecht. Um dieses Verhalten zu verbessern, könnte man nun versuchen, all das Wissen über den BHA in eine ausgefeiltere Regelungstechnik zu stecken. Wenn man dieses Wissen bloß hätte …
Eine kurze Liste von Dingen, die man über den BHA nicht weiß:
Das präzise Verhältnis zwischen Druck in den Kammern und der geometrischen Postur im Ruhepunkt (im Equilibrium)
Jegliche Art von Dynamik (nicht nur der Pneumatik selbst, sondern auch des sehr viel langsameren Zusammenspiels zwischen der Pneumatik und Geometrie)
Welche Länge des Arms bzw. der einzelnen Kammern ist überhaupt möglich? Wo liegen die Grenzen?
Und nicht zuletzt: Wie genau ist das Zusammenspiel der obigen Aspekte zwischen den einzelnen Kammern. Denn: Es besteht ein starker Zusammenhang!
Alles zusammen eine große Herausforderung … aber nicht unmöglich. Angenommen also, die Länge des Aktuators lässt sich messen und kontrollieren. Um nun die Endeffektor-Position (die Position des Greifers) zu kontrollieren … muss man die aktuelle Endeffektor-Position kennen!
Die Endeffektor-Position anhand der Geometrie des Roboters und der Stellung der Aktuatoren zu errechnen, nennt sich Vorwärts-Kinematik und ist für handelsübliche Roboter kein großes Problem, sondern einfache Trigonometrie. Der BHA gehört allerdings zu einer anderen Klasse von Morphologien, genannt Continuum Kinematics (also in etwa: kontinuierliche Kinematik). Dank seiner mechanischen Flexibilität besitzt dieser Roboterarm unendlich viele Freiheitsgrade, da jeder Bereich des Roboters unterschiedlich gebogen und gestreckt sein kann. Unendlich viele Freiheitsgrade können weder mit Sensoren gemessen noch berechnet werden.
Als wir unsere Arbeit mit dem BHA begonnen haben, planten wir nicht, die komplizierte Kinematik des BHA zu simulieren. Da wir uns im Kontext des BHA hauptsächlich mit Maschinellem Lernen beschäftigen, wollten wir die Endeffektor-Position schlicht messen, um sie benutzen zu können (tun wir auch). Dass wir trotzdem eine Simulation benötigen würden, stellte sich heraus, als wir Schwierigkeiten in der Visualisierung bekamen. Wir wollten nämlich darstellen, wie die räumlichen Koordinaten mit den Bewegungen des BHA zusammenhängen.
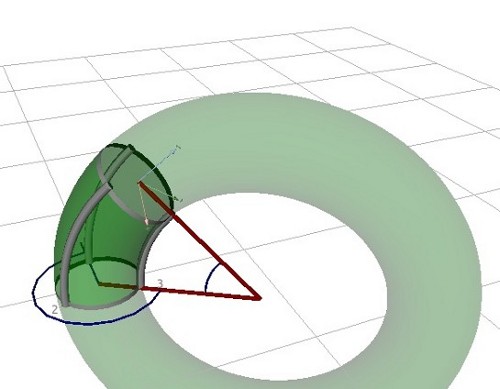
Da Visualisierung Kenntnis der Kinematik voraussetzt, begannen wir, sie anzunähern. Selbst wenn sich die Beugung und Streckung von unendlich vielen Freiheitsgraden nicht berechnen lässt, so lassen sich doch durch die Längensensoren einige Annahmen zur Beugung des Arms treffen. Die einfachste Art der Beugung ist eine kreisförmige; im drei-dimensionalen Fall entspricht dies einem Torus:
Torus-Modell zur Annäherung der Beugung des BHA
Das Bild zeigt, wie sich ein Segment mit drei Aktuatoren (in der Abbildung als graue Röhren dargestellt) entlang eines Torus verbiegt. Diese Geometrie kann mit drei Parametern beschrieben werden: zwei Winkel (in der Abbildung blau dargestellt) und der Radius des Torus (in der Abbildung rot). Diese drei Parameter können anhand der gemessenen Längen an der Außenseite der BHA-Segmente rekonstruiert werden. Sobald diese Parameter bestimmt sind, ist das Berechnen der Vorwärtskinematik und damit die Bestimmung der Endeffektor-Position (also der Position des Greifers) einfach. Ein Problem tritt lediglich im Grenzfall auf, wenn alle Längen gleich sind, wenn also alle Kammern gleich gestreckt sind. Diese Verformung kann durch einen Torus nicht dargestellt werden, obwohl der BHA zu solch einer Bewegung in der Lage ist. Auch für dieses Problem ließ sich allerdings eine einfache, numerisch stabile Lösung finden. Der BHA lässt sich somit durch Aufeinandersetzen dreier solcher Segmente darstellen und simulieren.
Die gezeigten Torusdeformationen sind sehr einfache Annäherungen des Arms im Vergleich zu komplexen Physik des Verformungs-Problems. Üblicherweise ist diese Art von Annäherung daher nicht hinreichend für diese Art von Robotern (siehe z.B. Trivedi 2008 2 ). Nicht jedoch für den BHA: Hier funktioniert die beschriebene Lösung sehr gut, in unseren Tests sehen wir einen durchschnittlichen Fehler von 1cm auf einer Länge von 1m. Nicht perfekt, aber absolut ausreichend für unsere Zwecke und außerdem durchaus konkurrenzfähig zu Lösungen in der Literatur.
Das folgende Video zeigt das simulierte Modell und unseren BHA:
BHA-Simulation
Der große Vorteil des benutzten einfachen Torus-Modells ist seine Geschwindigkeit in der Berechnung. Unsere Software-Bibliothek ist auf Basis dieses Modells in der Lage, die Vorwärtskinematik des BHA auf einem einzelnen CPU-Kern mehrere zehntausend Mal in der Sekunde zu berechnen. Auch wenn wir diese Simulation ursprünglich nicht geplant hatten, ist sie damit mittlerweile eine essentielles Werkzeug bei unserer Arbeit mit dem BHA geworden. Die interessanten Dinge machen wir weiterhin auch auf der echten Hardware, aber parallel lassen sich nun viele Dinge bequem vorberechnen und darstellen.
Die Kinematik-Simulation ist in C++ implementiert und als Open-Source-Bibliothek verfügbar. Über die folgende Seite kann sie heruntergeladen werden und enthält sowohl die Vorwärtskinematik als auch die gezeigte OpenGL-basierte 3D-Visualisierung: http://www.cor-lab.de/software-continuum-kinematics-simulation Wir freuen uns über Benutzer und Erfahrungsberichte.
Der folgende einfache Code-Schnipsel berechnet zum Beispiel die Vorwärtskinematik des BHA:
// create robot morphology with segment radii 0.1, 0.09 and 0.08 meters ContinuumRobotKinematics kinematics(RealVector(0.1, 0.09, 0.08)); // specify an end effector offset kinematics.setEndEffectorOffset(RealVector(0.0, 0.0, 0.14)); // this is the forward kinematics function: Mapping<RealVector,RealVector> fwdKin = kinematics.getForwardPositionKinematics(); // try out some posture (a combination of actuator lengths) RealVector posture = {0.2,0.24,0.24,0.2,0.24,0.24,0.2,0.24,0.24}; // this is the resulting end-effector position RealVector position = fwdKin(posture); // [-0.3808, 0, 0.686287]Neben der in diesem Artikel beschriebenen Kinematik-Berechnung und Simulation des BHA, haben wir in den letzten Monaten noch viele weitere spannende Dinge mit dem BHA gemacht, die wir auf der Automatica-Messe im Mai in München zeigen werden: Um zu sehen wie wir trotz der zahlreichen obigen Probleme mithilfe maschineller Lernmethoden den Greifer auf dem echten BHA im Arbeitsraum zu kontrollieren gelernt haben, lohnt sich also ein Besuch unseres Standes auf der Automatica in München: Stand 427 und 429 in Halle B3, vom 22. bis 25. Mai.
So, bevor ich mich übers Wochenende verabschiede, noch ein paar Links, die sich hier angesammelt haben. Ein Ein-Mann-Senkrechtsrarter der NASA, Internet für Roboter, aufmerksame Bodenbeläge und mehr …
Ein-Mann-SenkrechtstarterDie NASA hat Pläne für einen elektrisch betriebenen Ein-Mann-Senkrechtstarter namens Puffin (Papageitaucher). Beeindruckend sind die angegebenen Kennzahlen: Die Flughöhe ist – begrenzt durch den Akku – mit maximal 9100 Meter angegeben, die Reichweite mit 80 Kilometern bei beachtlichen 240 Stundenkilometern.NASA entwickelt Ein-Mann-Senkrechtstarter(heise online, Malte Kanter, 31. Januar 2010)SchreitroboterForscher aus Göttingen haben einen sechsbeinigen Roboter entwickelt, der das Laufen lernen und automatisch an seine Umgebung anpassen soll. So soll er zum Beispiel lernen, bei Steigung langsamer und mit kleineren Schritten zu laufen als im offenen Geländer. „Die Forscher modellieren das Herzstück der Gangsteuerung, eine Art neuronalen Schaltkreis, nämlich mit den Mitteln der nichtlinearen Dynamik.“Roboter-Nervensystem mit Chaos-Steuerung(Telepolis, Matthias Gräbner, 24. Januar 2010)Maschinelles LernenDie Eindhoven University of Technology hat in Kooperation mit sechs anderen europäischen Instituten ein europäisches Forschungsprojekt an Land gezogen, das ein World Wide Web for Robots entwickeln soll, das Robotern eine weltweite Wissensbasis zum Austausch von Erfahrungen und gelernten Aktionen bieten soll.Robots worldwide will learn from each other (englisch)(TU Eindhoven, 13. Januar 2010)Assistenzsysteme„Notruftechnik, die von selbst Hilfe holt, Bodenbeläge, die gefährliche Stürze erkennen und melden, oder Roboter, die das Frühstück ans Bett bringen – intelligente Assistenzsysteme bieten älteren Menschen die Chance auf ein sicheres Leben zu Hause.“ Forschung zu Assistenzsystemen im Dienste des älteren Menschen, gefördert vom Bundesministerium für Bildung und Forschung.Forschungsministerium baut Förderung für Roboter-Assistenzsysteme aus(MaschinenMarkt, Stéphane Itasse, 2. Februar 2010)Humanoide RobotikNasa und General Motors haben einen humanoiden Roboter für den Einsatz im Weltraum entwickelt. „Er hat einen Torso und zwei Arme, […] sitzt auf einem festen Ständer. Laufen kann der R2 also nicht.“ Der Einsatz im Weltraum ist anhand der gerade erfolgten Absage einer weiteren bemannten Mondmission fraglich, General Motors will den R2 aber ohnehin auch in seinen Werkshallen einsetzen.Robonaut 2 – Roboter für die Fabrik und das Weltall(Golem, Werner Pluta, 5. Februar 2010)
Hinweise zu lesenswerten Artikeln nehme ich jederzeit gerne entgegen anbotzeit@ohmpage.org