(this article is also available in English)
Schon vor gut einem Jahr habe ich über Festos Bionic Handling Assistent (BHA) geschrieben, der damals frisch mit dem Deutschen Zukunftspreis gekrönt war. Wir haben einen von diesen Robotern bekommen und im April letzten Jahres haben wir bereits hier über unsere ersten Gehversuche und die Simulation des Roboters geschrieben. In diesem Artikel wird es nun darum gehen, wie wir von Babys gelernt haben, den Roboter zu kontrollieren.
Vor einigen Wochen wurde der BHA in der Sendung mit der Maus gezeigt. Wer das Video bis zu Minute 5:00 verfolgt, bekommt jedoch den Haken mit: so faszinierend der Roboter, insbesondere der BHA, auch ist … es ist ebenso kompliziert, ihn zu bewegen.
Die Sendung mit der Maus – Festos BHA und RobotinoIn der Sendung und bei den meisten Vorführungen des Roboters steht daher jemand an einer Fernbedienung, oder öffnet und schließt händisch die Ventile, wie zu Beginn des Videos zu sehen. Von einem praktischen Einsatz, bei dem der Roboter eigenständig Aufgaben erledigt, ist das noch meilenweit entfernt.
Das liegt unter anderem daran, dass der Rüssel anders ist, als andere Roboter. Seine elastischen Bewegungen sind sehr schwierig und nur annähernd in mathematische Gleichungen zu fassen. Genau diese Bewegungsgleichungen benötigen aber die klassische Verfahren zur Robotersteuerung. Selbst unser Modell reicht dazu kaum aus, denn es kann keine Auskunft über die Reichweite der vielen Aktuatoren liefern. Diese müsste man sehr genau kennen um den Roboter (klassisch) ansteuern zu können: es ergeben sich schnell sehr große Fehler, wenn der Regler einem Aktuator einen Befehl gibt, der außerhalb seiner Reichweite liegt.
Was das Ganze noch schwieriger macht sind die Verzögerungen im Bewegungsverhalten: der Roboter bewegt sich mittels Luftkammern, die mit Druckluft aufgeblasen werden, die aber erst mit Verzögerung in den Kammern ankommt. Danach dauert es einige Zeit, mitunter bis zu 20 Sekunden, bis der Roboter seine neue Postur erreicht und sich stabilisiert hat. Diese Verzögerungen machen viele der sonst auf Robotern verwendeten Regler praktisch nutzlos, da sie schnelles und exaktes Roboterverhalten benötigen.
Schwierig … aber dafür gibt es maschinelle Lernverfahren, von denen es unzählige Methoden gibt, um Roboter Bewegungen lernen zu lassen. Zunächst muss man den Roboter seinen Bewegungsraum explorieren lassen, also ausprobieren welche resultierenden Bewegungen durch verschiedene Motorkommandos hervorgerufen werden. Da liegt allerdings schon die nächste Krux mit dem BHA, denn: es gibt sehr, sehr viele verschiedene Motorkommandos. Die Standard-Ansätze zum Lernen erfordern, sie alle auszuprobieren. Auf dem BHA benutzen wir aktuell neun Aktuatoren (die Luftkammern). Möchte man pro Aktuator nur 10 verschiedene Kommandos ausprobieren, ergeben sich bereits eine Milliarde (10^9) Kombinationen. Es würde Jahrzehnte dauern, würde man ernsthaft versuchen die alle auf dem Roboter zu explorieren. In der Praxis würde man daher eher zufällige Kommandos auswählen, und einfach irgendwann aufhören. Natürlich ändert das aber auch nichts daran, dass man eigentlich alle Kommandos ausprobieren müsste, damit das Bewegungslernen funktionieren kann.
Was tun?
Um diesem Problem zu begegnen, haben wir uns Inspiration aus der Biologie geholt. Die Aufgabe, den BHA-Rüssel kontrollieren zu lernen, ist nämlich in vielerlei Hinsicht der Aufgabe von Babys sehr ähnlich, in den ersten Lebensmonaten zu lernen, ihre eigenen Gliedmaßen zielgerichtet zu bewegen. Sie müssen dafür lernen, 600 Muskeln zu koordinieren, und sind dabei unglaublich effizient. Was ist also der Trick, den wir lernen müssen, wenn wir unsere Experimente mit dem BHA ähnlich effizient durchführen wollen?
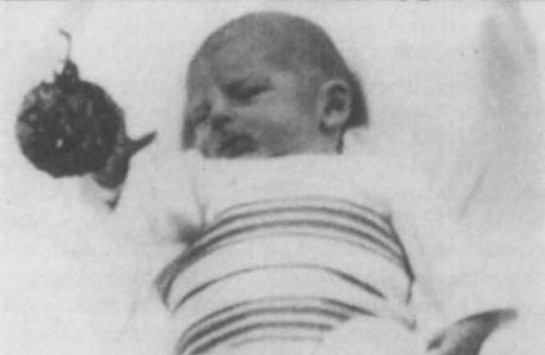
Einen Hinweis liefert eine wegweisende Studie von Claes von Hosten aus dem Jahr 1982. Diese Studie konnte zeigen, dass selbst Neugeborene sich nicht ‐ wie es zuerst scheint ‐ zufällig bewegen, sondern von Beginn an zielgerichtet in Richtung bewegter Objekte greifen. Das folgende Bild zeigt dies unglaublicherweise bereits bei einem wenige Tage alten Baby:
Diese Erkenntnis wurde lange von der Machine Learning Community ignoriert, und sollte uns den entscheidenden Hinweis geben. Der von Matthias Rolf entwickelte Ansatz Goal Babbling, versucht nicht mehr durch zufällige Bewegungen den Bewegungsraum zu explorieren (Motor Babbling), sondern tut es von Anfang an zielgerichtet [Rolf et al., 2011]. Die Ergebnisse in Simulation waren vielversprechend, und haben gezeigt, dass dieser Ansatz auch mit 50 Freiheitsgraden zurecht kommt und nicht einmal mehr Zeit benötigt als für einen Roboter mit nur zwei Gelenken. Das ist ein entscheidender Vorteil gegenüber dem zufälligen Explorieren des Raumes, dessen Zeit zum Explorieren exponentiell mit der Anzahl der Dimensionen steigt. Mit Goal Babbling erhalten wir erste brauchbare Resultate bereits nach wenigen hundert Bewegungen, was sogar mit der Geschwindigkeit menschlichen Lernens vergleichbar ist [Sailer and Flanagan, 2005]. Wir können also offenbar wirklich mit der biologischen Vorlage das Lernen massiv beschleunigen! Zeit also, das biologisch-inspirierte Lernen auf dem biologisch inspirierten Roboter anzuwenden.
In unseren ersten Experimenten lernte der Roboter lediglich einfache Bewegungen des Greifers nach links und rechts. Nicht besonders nützlich, aber trotzdem beeindruckend als Live-Demonstration, denn der Roboter konnte innerhalb von zwei Minuten eigenständig lernen, seine neun Kammern zu koordinieren und diese Bewegung auszuführen. Schnell zeigte sich außerdem, wie gut das Verfahren mit Hardware-Defekten umgehen konnte, obwohl wir wahrlich nicht vor hatten, das herauszufinden. Eines Tages während der Experimente stellten wir jedoch ein kleines Loch in einer der Luftkammern fest, durch das Luft entwich: die Kammer konnte sich nicht mehr aufblasen. Schlimmer noch: die Kammer bewegte sich passiv wie eine mechanische Feder mit, was die Bewegung des gesamten BHA-Rüssels beeinflusste. Das Lernverfahren scherte das kaum. Es lernte einfach die anderen Aktuatoren entsprechend einzusetzen ‐ zusammen mit der passiven Bewegung des defekten Aktuators. Wohlgemerkt: wir mussten dem Verfahren dafür nicht mitteilen, dass etwas defekt war. So einfach kann es manchmal sein!
Eine ähnlich gute Entdeckung machten wir, als jemand den Roboter hin und her schob, während er grade explorierte und lernte. Durch das Anschubsen des Roboters konnte man ihm tatsächlich unter die Arme greifen und ihm zeigen, wie sinnvolle Bewegungen aussehen. Schiebt man ihn in die Richtung, in die er sich gerade bewegen will (also die richtige Richtung), spürt man bemerkenswerterweise kaum Widerstand vom Regler. Das Lernen geschieht in diesen Momenten so schnell, das der Roboter die Bewegung schon während des Führens in den gelernten Regler einarbeitet. Folglich reicht es aus, ihm die Bewegung ein einziges mal zu zeigen. Das Ganze ist überhaupt nur möglich, weil das ziel-gerichtete Explorieren und sehr schnelles kontinuierliches Lernen des Goal Babblings mit dem leichten, nachgiebigen BHA-Rüssel aufeinander treffen. Preis-gekrönte 1, biologisch inspirierte Hardware und preis-gekröntes 2, biologisch inspiriertes Lernen.
Bei dem gesamten Vorhaben leistete uns die vorher entwickelte Simulation des Bewegungsverhaltens gute Dienste. Auch wenn das Lernen und Explorieren auf dem echten Roboter stattfand, war die Simulation für allerhand Visualisierungen und zusätzliche Vorhersagen nützlich. So ließ sich nun die Bewegung des Roboters bezüglich selbst-generierter (und ausschließlich virtuell existierender) Ziele während des Lernens darstellen, und das Lernen auf dreidimensionale Ziele (anstatt nur links/rechts) erweitern. Wir konnten nun Einblick in das Lernen nehmen und live während des Lernens vorhersagen, wie gut der gerade lernende Regler verschiedene Positionen im Raum anfahren kann. Wir lernten dadurch, dass sich das Lernen auf dem echten Roboter ganz ähnlich entfaltet wie es unsere ersten Simulations-Experimenten 2010 bis Anfang 2011 (noch komplett ohne den BHA) gezeigt haben.
Biologisch inspiriertes Lernen auf einem biologisch inspirierten RoboterAuf dem Rüssel liefert Goal Babbling schnell nützliche Ergebnisse. Nach dem Lernen lässt sich der Greifer mit ca. 2 cm Genauigkeit im Raum positionieren. Das ist nicht direkt perfekt, aber reicht in vielen Fällen schon aus, da der flexible Fin-Gripper Gegenstände großräumig mit seinen elastischen Fingern umschließt. Um den Rüssel so schnell und gezielt wie im Video bewegen zu können, darf man nicht auf Feedback (also Bewegungsantworten) vom Roboter warten, da das bei der Pneumatik zu lange dauert. Solch einen Regler, der ohne Feedback auskommt, liefert uns das Lernen. Dadurch weiß der Roboter sofort, wo er hin muss, anstatt sich langsam und Schritt für Schritt ans Ziel heranzutasten. Feedback ist dann lediglich eine zusätzliche Hilfe, die wie in der letzten Sequenz im Video zu sehen, die Genauigkeiten auf 6-8 mm erhöht. In Anbetracht der Tatsache, dass der Rüssel selbst permanent ca. 5 mm hin- und herschwankt, ist das beachtlich.
Erwähnenswert ist außerdem: das Ganze funktioniert nicht nur einmalig und im Video. Wir haben sehr ausgiebige Experimente dazu gemacht, und es funktionierte in jedem Durchgang. Das Lernen von links-/rechts-Bewegungen haben wir regelmäßig in Live-Demos gezeigt, in denen der Roboter binnen 1-3 Minuten seine Bewegungen lernt. Unter Anderem haben wir dies live auf der Automatica 2012 in München gezeigt, auf der das Live-Lernen mit dem Roboter und dem Objekt-Tracking aus dem Video vier Tage lang jeweils acht Stunden lief.
Die gute Nachricht lautet also: es funktioniert! Und es funktioniert robust!
Festos Bionic Handling Assistant ist ein großartiger, spannender Roboter. Er ist nicht nur ein Hingucker durch seine Ähnlichkeit mit dem Elefantenrüssel, sondern seine Struktur macht auch den Umgang und die Interaktion mit ihm natürlich und sicher. Um ihn allerdings auf ähnliche Art und Weise kontrollieren zu können, wie wir es mit anderen Robotern tun, mussten wir einige Hürden überwinden: Ausgangspunkt war ein Roboter ganz ohne Modell und nur mit einfacher Druckregelung. Stück für Stück haben wir ein Vorwärtsmodell der Kinematik, Simulation und Längenregelung hinzugefügt. Der entscheidende Punkt war allerdings, maschinelles Lernen, vor Allem das durch Beobachtung von Babys inspirierte Goal Babbling einzusetzen, das erstaunlich schnell lernt, den Roboter zu kontrollieren.
Jetzt, da wir den Rüssel kontrollieren können, um Objekte zu greifen und zu bewegen: Für welche Aufgaben sollten wir ihn jetzt unbedingt einsetzen?
Kontakt:
Dr.-Ing. Matthias Rolf, CoR-Lab – Bielefeld University, mrolf@cor-lab.uni-bielefeld.de, Emergent Robotics Lab, Osaka University
Prof. Jochen Steil, CoR-Lab – Bielefeld University, jsteil@cor-lab.uni-bielefeld.de